Cached Credentials: вход в Windows под сохраненными учетными данными при недоступности домена
Когда доменный пользователь входит в Windows, по умолчанию его учетные данные Cached Credentials: имя пользователя и хэш пароля сохраняются на локальном компьютере. Благодаря этому, пользователь сможет войти на локальный компьютер, даже если контроллеры домена AD недоступны, выключены или на компьютере отключен сетевой кабель. Функционал кэширования учетных данных доменных аккаунтов удобен для пользователей ноутбуков, которые могут получить доступ к своим локальным данным на компьютере, когда нет доступа к корпоративной сети.











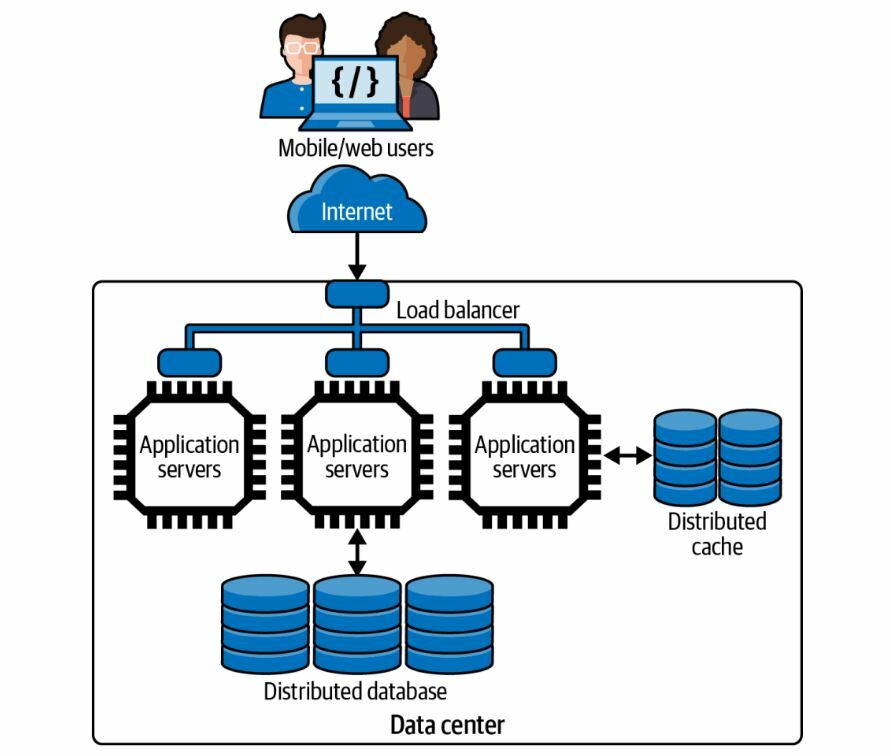
Кэширование означает хранение контента, генерируемого в цикле запрос-отклик, и повторное использование его при ответе на подобные запросы. Кэширование часто является самым эффективным способом повысить производительность приложения. При помощи кэширования, веб-сайты, работающие на одном сервере с одной базой данных, могут выдержать нагрузку в несколько десятков тысяч конкурентных пользователей.
- Использование кастомных аннотаций
- В начале использования Git часто возникает вопрос: «Как заставить Git больше не отслеживать какой-либо файл или несколько файлов?
- Выполните обновление до Microsoft Edge, чтобы воспользоваться новейшими функциями, обновлениями для системы безопасности и технической поддержкой.
- В сфере вычислительной обработки данных кэш — это высокоскоростной уровень хранения, на котором требуемый набор данных, как правило, временного характера.
- Сравнение режима кэширования Exchange и режима "в сети"
- Поиск Написать публикацию. Время на прочтение 12 мин.
- Некоторые задачи по извлечению или обработке данных, выполняемые вашим приложением, могут потребовать больших ресурсов ЦП или занять несколько секунд.
- В этой части я подробно рассмотрю принцип работы каждого плагина, о которых говорил в первой части , а также приведу код с доработками для закрытия проблем плагинов. Кратко все преимущества и недостатки, основные выводы я уже сделал в первой части статьи.




Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL , чем отличаются функции cache и persist , из чего состоит план запроса и каковы альтернативы кэшированию данных для повторного использования вычислений. Кэширование данных в Apache Spark SQL — это весьма популярный способ повышения производительности приложения за счет повторного использования некоторых вычислений. Однако, чтобы эффективно использовать его, следует помнить о некоторых особенностях настройки Spark-приложений. Часть этих рекомендаций мы разбирали вчера , на примере перехода от локальных Pyhon-скриптов к распределенным заданиям PySpark.